- Data Continuum
- Posts
- ELT vs ETL: What really is the difference?
ELT vs ETL: What really is the difference?
Understand with business examples
Sasi SB
December 10, 2023
It’s not enough to just know the expansion of the terms ETL and ELT
Even though the full forms are pretty intuitive, there’s more to the story!
When asked about the difference in a job interview, you can’t just say the full form and expect it to suffice right?
A common problem that organizations face is how to gather data from multiple sources, in multiple formats.
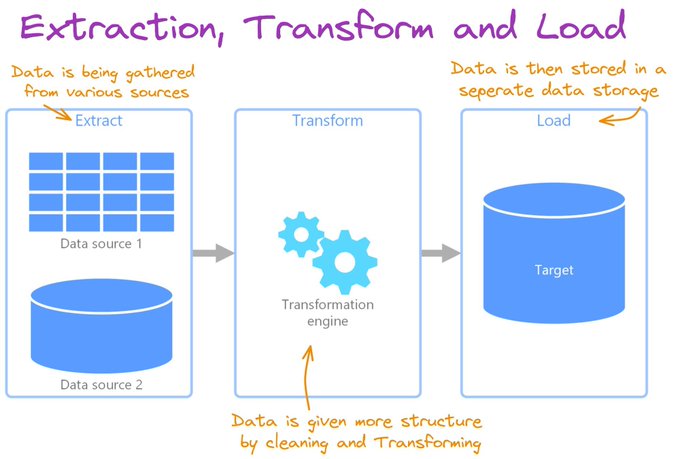
Extract, transform, and load (ETL) pipelines first collect data from various sources.
It then transforms the data and loads the data into a destination data store.
It often involves using staging tables to temporarily hold data as it is being transformed and ultimately loaded to its destination.
Let's see an example to understand better:
Your organization has started to explore more about historical trends and patterns of the data.
Currently, the organization only has a transactional database (OLTP) for the product.
Running these heavy analytical queries runs the risk of breaking the database.
So, you replicate the data on a database designed specifically for analytics (OLAP) to power these heavy queries.
You build an ETL pipeline to replicate data from the transactional database to the analytical database, including some data transformations to make it easier to use.
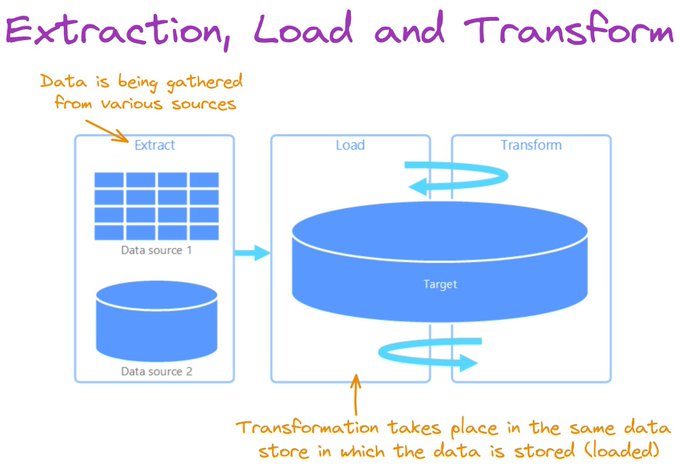
Extract, load, and transform (ELT) differs from ETL solely in where the transformation takes place.
Instead of using a separate transformation engine, the processing capabilities of the target data store are used to transform data.
This simplifies the architecture by removing the transformation engine from the pipeline.
Now let's look at a Business Example:
Your organization purchases third-party data to supplement your organization's data.
While this data is useful, the vendor provides extremely messy tables (Which is usually the scenario).
Since this data is for R&D purposes, there is no defined business logic available.
You build an ELT pipeline that extracts the raw data from the third-party vendor and loads it into the data lake.
The data science team then determines which parts of the data are valuable, and builds data transformations on top of the data in the data lake for the workflows.
This week’s cool finds
Here is a FREE Python Study Bot for those who want to Fast-track their learning!
Reply